
Science and Decisions
A primer for building data intuition in product development

Key Takeaways:
We use evidence to help us understand the world we live in and the people who use our products.
Evidence helps us make better decisions with more certainty.
There will always be uncertainty in our decision-making, because the cost of omniscience is infinite.
Living with some uncertainty when we make decisions is ok. We just need to understand the risk vs. cost trade-off.
Decision Science is the practice of using scientific methods to help make business decisions. If you are a product owner, marketer or business leader, having a foundational understanding of Decision Science can help you gain confidence with data interpretation and narrative-building.
To understand how, let’s start by talking about what science is itself. Roughly speaking, science is:
”the pursuit of understanding the universe following a systematic methodology based on evidence.”
What does that have to do with product development? Whenever you want to run an A/B test, or look at a dashboard, or ask the data science team to build a model, you are using data as evidence to help understand the business and the people who use your products. The systematic methodology is the statistics math-y bit, but we don’t really need it at this stage so I’ll leave it out of scope for this post.
The key point in the definition above is that science, including the science used to learn about our users, is the pursuit of understanding, which means that the work of a data scientist is always more of a journey than a destination.
Take the story of Isaac Newton, who realizes that a falling apple is evidence for gravity, and uses that evidence to generate the hypothesis that gravity is a truth of the universe. If life was a Hollywood film, this would be the moment where a chalk-dust-covered man in a lab coat races to a blackboard, draws out a bunch of math and says “behold! I have discovered gravity!”
As you might have guessed, this is not how science works. Really ever. Today’s understanding of gravity is far more complicated than what Newton developed, and yet still holds some mystery.
Instead, pieces of information are gained throughout time, which are then woven together to form a better theory that describes what we think the “truth” is. Each time we gain evidence, more hypotheses are generated, which directs us where to go look for more evidence. Science leverages the back and forth dichotomy between theories and evidence, and through its practice helps us understand what is going on in the universe.

Coming back to business applications, collecting evidence in the form of data to learn about a “truth” about our users works in the same way. For example, if I measure how many users we had yesterday who had also used the product some time in the past prior to that, I’ve gained evidence that for some people, the product is worth coming back to. That isn’t the whole story, but we’ve gained some knowledge that helps us on our journey, and that is still useful.
The pursuit of knowledge for its own sake is great, but Decision Science is all about using knowledge to make better decisions.
This is where it’s important to keep in mind that the process of gaining knowledge is always a journey, not a destination, which means it’s never complete. The reality is that we’re often forced to make decisions well before we have all the information.


When data scientists respond to questions with caveats and non-answers, it can feel like progress with the data team is slow and inefficient. If this sounds familiar, you might have been inclined to ask for more resources or a bump up in your project’s priority.
Instead, what if we admit that there will always be some uncertainty?1 It turns out that this is one of the most fundamental concepts for building data intuition. It also happens to be the essence of statistics, the math we use to quantify uncertainty, but that’s still out of the scope for this post.
This is the world we live in, at all times, and when you are looking at data to help you make a decision, it is the scientist’s hat that you must wear.
Implications for Product Development
How we can ever feel good about the decisions we are making, if nothing is ever certain? Luckily for us, some things are less uncertain than others, and the more effort we put into learning, the more the uncertainty is reduced.
Besides the decision you are making for a particular business question, there is another decision you have the opportunity to make, based on how much uncertainty you are comfortable with. This simple change in framing also gives you the agency to turn the dial on how much data science team support you really need.
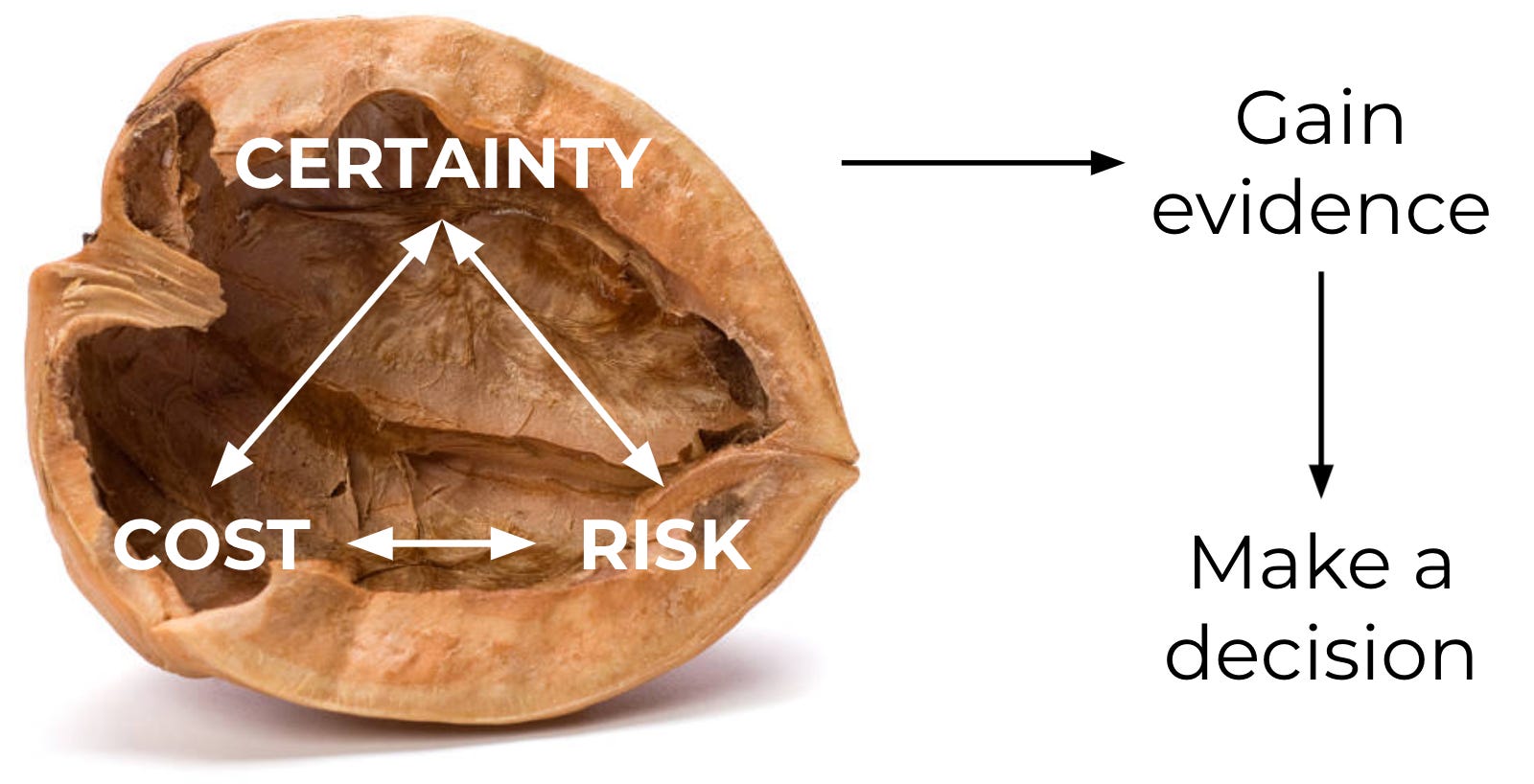
Determining how much uncertainty you are comfortable with for a particular decision is more art than science, but it is dependent on two main factors: Cost and Risk. The cost of gaining knowledge, vs the risk of being wrong.
Case study: New App Refresh
Imagine you are responsible for completely refreshing a stagnant app that has been in maintenance mode for a while. The refreshed product will get a new name, Android and iOS engineers have been working hard on refactoring the code and modernizing it, UX has created some fantastic new graphics and user flows, and you’ve planned the launch with the marketing team. Even though the user base is relatively small, you still want to try to retain the users you have with a better experience post-migration, and hope that with marketing efforts, you’ll gain many more new users as well. You go ahead and release the new refreshed app, and everyone celebrates their hard work. Huzzah!
With all that effort, you want to use data to measure whether or not it was worth it. In fact, business leaders of the company have several (too many?) initiatives, and now that the new app has launched, they want to make a decision about how many engineering, marketing and UX resources your product will get moving forward. You go to the data team for some help, and ask:
“Has the refreshed app been a success since its release?”
Usually “success” in this kind of situation means “I want to know that when we launched the new thing, it was some amount better for the company than if we had done nothing at all.” The first step is to set a baseline to compare against. The baseline represents the “if I had done nothing at all” scenario.
There are two universes here, the universe in which we didn’t refresh the app and let it stay in maintenance mode (this is the baseline), and the universe we’re in now, where we have released the refreshed app.

After discussing with your data team, you pick a metric, say “number of new users (over some time period)”, because we hope we’ll attract more people with this better version of the product. In the universe where we don’t ship a new app, we probably still have some small amount of new users, though maybe the trend is expected to be flat.
All we need to do is compare one trend to the other, measure the difference between the two some time after the launch, and if we see a significant increase, we can say we succeeded!
Sadly, due to the lack of multi-dimensional transportation devices in this universe, we’ll never know for sure what would have happened in the other universe. Somehow, we have to measure the difference between the number of new users we have now after the new app release against the number of new users in the universe that never was.

So there’s no way to measure the baseline directly, but at least we can estimate it. Estimates always have some uncertainty, and if we are wrong about the baseline, then we will either over- or underestimate the difference from our success metric of increased new users.
Make a decision before the decision
As the product owner of the app, you have the power to decide how the baseline is estimated, with different approaches bringing different levels of certainty. Here are some ways you could do it:
You could ask your neighbor who happens to be a psychic to pick a number from 1 to a million.
You could make a pretty good assumption that the past can tell us at least something about the future. You could measure the number of new users acquired during the days leading up to the launch, and assume that if you had done nothing it would have remained a flat trend moving forward in time.
Sometimes we have different acquisition trends depending on weekdays vs weekends, or something disruptive in the world recently changed the behavior of the market. So looking at say, number of new users we got one year ago might be a good way to get rid of that seasonal effect.
You could eyeball a way to combine that seasonal estimate with the trend in the days leading up to the launch.
You could ask a Data Scientist to do a statistical forecast from the new user data up to and right before the launch, which is a more mathematically sound way of combining seasonality with more recent trends.
Or, if you really want to be as sure as possible what would happen if you didn’t launch the new app, you could just revert to the old version. That may sound absurd, but it’s not uncommon that this is actually a choice, especially when a large risk is involved. More on that later.
We naturally think about all of these options on a spectrum of certainty without realizing it.

You also might be thinking about the resources needed to do each of those estimates. For the method that is least likely to be anywhere near the truth, all you need is to walk next door and ask your psychic neighbor a simple question. For the next three estimate methods, you could probably leverage analytics tools, dashboards or prior art to dig that up yourself, assuming you know where to look. For the forecast, you’ll need a data scientist, which is an extra resource and probably takes a bit more time. For pulling back the release, you need to survive the wrath of your business leaders.
Learning always comes at a cost. Cost can mean time, money, resources, or even cost to the company of not doing the thing. Some types of analyses are time-costly by definition, like an experiment that measures 28 day retention needs at least 28 days, not including setup or analysis time.

Risk is the other side of the coin. Every decision comes with risk. If you blindly launch a new product without any upfront studies, the risk can be anywhere on a scale from making people mildly annoyed to tanking the entire company.
Gaining evidence reduces risk, but there are diminishing returns with the cost of gaining more knowledge, so there is usually a point at which you have enough evidence to make the decision, even if you aren’t 100% certain.

Certainty, cost and risk. When a product decision needs to be made, these are the three interdependent values that need to be weighed against each other. Certainty, cost and risk are all on a spectrum; they are knobs that you as the decision-maker can turn, and they will inform what kinds of studies you either choose to perform yourself or ask of the data science team. And that is Decision Science in a nutshell.
A good book about this subject is Annie Duke’s “Thinking in Bets.” Life is like poker, not chess.
I think I've drawn that do some data stuff/make a hypothesis wave a dozen times lately... we've started describing it as inhale/exhale phases of research. This is great, please write more!!
All I learned by reading this, is that we have a heavy need for multi-dimensional transportation devices. 😂😂 But seriously, excellent post. going to forward this along to my team.