
Thinking about evolving your data stack
Why does everything feel so difficult?


Besides being responsible for people, processes and evangelization, data leaders need to find ways to make the data-to-insight-to-impact loop more efficient, both for their teams and for the sake of company-wide data literacy.
While the current data stack might “work”, it’s likely been cobbled together over time based on short-to-medium-term needs, and probably feels insufficient for where you need to be today. Maybe you need to automate some manual processes that are unnecessarily slowing the team down. Maybe you are wondering whether it’s finally time for a dreaded data warehouse migration. Everyone is talking about the modern data stack, and you want to feel current too.
Just as the industry has grown in its data maturity, the landscape of data tooling choices has exploded in size. If you are the resident expert driving the data strategy at an organization where the data platform needs to evolve (or …exist?), or are the first data person at a company, say, it’s likely that everyone is looking to you to make sense of it all.
I’m not here to contribute yet another data infrastructure diagram, but to give some guidance to those who need to drive some strategic decisions/choices around the data platform at their company. Really, it’s about creating a decision framework that makes it possible to feel good about the choices you will ultimately have to live with, and leveraging a product mindset while doing so.
Get out of the rut of being stuck with what you have, and determine what you need by looking at the end goal: Business Objectives
The first iteration of your end-to-end data platform was likely built in the same direction as the data flows: You establish ingestion pipelines of raw data into some warehouse, have analytics engineers clean it up and design curated tables updated on some regular cadence, create access patterns for data scientists to do their thing, and throw a BI tool on top to make reporting possible for non-data people. Maybe you’ve gone the extra mile and added an experimentation layer as well.
This bottom-up data modeling approach starts with the data sources, where the system is built before fully knowing what you might do with the data, also known as the “just start collecting all the stuff and we’ll worry about using it later” strategy. The architectural design starts with the question “How do we bring the data we have to somewhere where people can access it?” and only later asks “What kinds of business outcomes can we leverage it for?”
This is a fairly straightforward approach in practice, but from a higher-level perspective, an organization can get stuck working with data they have, making it harder to get out of the architectural corner they might have painted themselves into.
A less intuitive approach that requires more upfront, intentional effort starts with business outcomes. Here, the architectural design begins with high-level questions such as “Where does the company need to be in X years?” followed by “What clarity do we need to get in order to move towards those goals?” and then lastly “What data do we need in order to address our hypotheses for those business questions?” For example, a growth team might need to understand where people are dropping out of the funnel during new user acquisition and product onboarding. The data needed to understand this might include website usage data, in-product messaging data, survey data, payments data from a third party app, and product usage telemetry, not to mention non-quantitative insights coming from research practices like user interviews. Though data may come from completely different sources, it should be thought of as a coherent body of information that supports a higher-level business problem.
There are two reasons why this is a better approach. First, it can help identify gaps in the data infrastructure you already have. Secondly, because the focus is on the business outcomes, the goal becomes less about “collecting all the data” and more about finding the best way to bring the most relevant knowledge together - no matter where it comes from - and into the hands of the people who need to make decisions.
One last note on this subject, it is extremely important at this stage to make sure your business questions are actually business questions:
NO: “We need to make dashboards” or “We need to run experiments.”
BETTER: “We need to track our progress towards quarterly goals with KPIs such as new user acquisition, ARR etc,” or “We need to test variations in our onboarding process to increase user retention.”
BEST: “How do we know if we are on track to meet our customer acquisition goals this year?” or “Where are people dropping out of our onboarding process, and where should we focus our efforts on making that better?”
Who are your data customers, and what do their “ideal” workflows look like?
Once you know your end goal, it’s time to catalogue who the data customers are, what success workflows look like for them and what they need in order to achieve that success. This should all be done with the ideal state in mind, and there is no reason not to go beyond immediate band-aids and think big (we’ll get to the “where we are today” and how to prioritize what to tackle first later on). For simplicity, I’m going to use a generic analytics stack as an example.
Keep in mind that a typical data stack doesn’t just have one end customer. Data engineers, analytics engineers, data scientists and analysts are also going to use the platform they are building, and you should consider them as important customers with real needs as well. For example, a data platform engineer responsible for provisioning/maintaining a cluster in an AWS shop will have different needs than a data scientist focused on understanding customer behavior, and they will have different needs than an analyst creating daily reports for a marketing executive. It also helps to frame the personas of your data customers by what skills each of them have, and what their ideal workflows look like. Later, when making tooling choices, you can look back at your full set of data customers and make sure you aren’t over-rotating on support for one while cutting the arm off another.
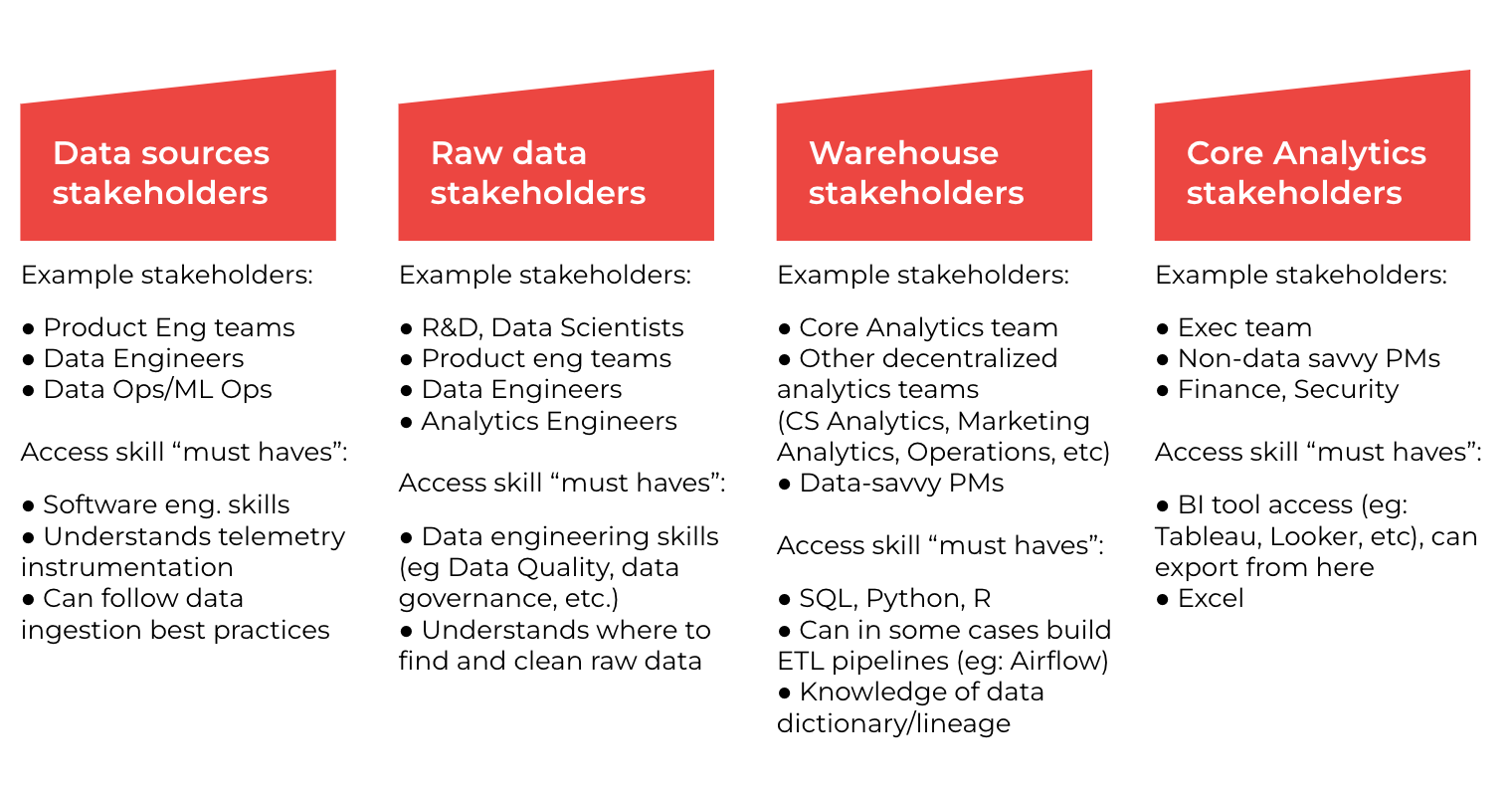
The same is true for data customers outside the data org. It’s worth pausing here and thinking about how to scale data literacy: What kinds of problems should the data experts be focused on versus what kinds of repeated questions should be addressed with self-serve tools for non data-practitioners?
I also like to put together user stories that state the requirements/needs for each of the data customers who will use the stack, which helps me visualize what “good” looks like end-to-end. For example, if there is a need to enable business leaders to explore trends in top-line metrics in a self-service tool, I might put together (and/or crowdsource) a set of user stories like this:

Other things to consider when auditing the needs of your data customers:
Where do these different people live in the organization? Are you all on a centralized data team? Or taking a distributed, data mesh-y type approach? Are there different analytics teams spread throughout the company? (e.g. Marketing, CS, Product, Operations, etc). How will you keep them aligned as they create different data narratives?
Cadence: How often should they be accessing the data? Daily? Monthly? Real-time? This will impact your SLA with your customers.
What data access patterns really ought to be automated?
Given this set of data access needs, what are the technological/organizational challenges associated with each of them?
Now that you know what “ideal” looks like, it’s time to do a full end-to-end data platform audit to determine where you are today. For each of the user stories you created, catalogue what pain points exist and where they are coming from. Look for causes, not symptoms. If you’re not sure what they need, do a listening tour and find out what the biggest pain points are for each of your data customers.
Which teams need to align roadmaps? Is Data Engineering centralized with Data Science? What about their relationship with software engineering? (e.g. frontend client telemetry instrumentation, backend services, etc.)
Are there any processes that you can establish for “free” that can help make data developers more efficient? (e.g. ammending a new product feature roadmap to always add in this telemetry with this format)
Know your context: are you a small startup that has a greenfield opportunity to build a new data stack? Mid-size company with data all over the place that needs to migrate…something?
Prioritize by determining what you are optimizing for
You can’t solve for every pain point overnight. This is the time to de-scope, or create a longer-term roadmap where progress is obtained in reasonable stages.
Figure out your “must haves” versus your “nice to haves”. Write what you are optimizing for in a one-sentence vision statement (e.g. “We need to scale data access to more people in the company beyond the data team by building an intuitive, trustworthy, self-serve data BI tool.”)
Determine the trade-offs between what you have today and what you need to buy/build/borrow. Think about your current state of data debt. Do you really need a new tool, or can you change the way you’re doing something internally for free?
Build the decision framework
Start writing up a decision document1 that states the problems to be solved in priority order and the different choices to be made. A decision document should include:
What ideal looks like
A summary of the current state today
A list of customers (both internal and external to the data team) who will be affected by this decision
Your recommendation
A space for sign-offs from the people making the decision (e.g. RACI)
Options considered (listed as Option 1, Option 2, etc. with each of their benefits/risks)
You can also add an appendix with your user stories from your data customers for completeness
There’s a lot of content out there to help you compare options if you do determine that you need to sign up for new tooling,2 so I’ll just end with some last points to consider:
Cost beyond pricing: When determining what you can afford, there is more to consider than just what you pay for the service. It’s important to think of all of the cost trade-off considerations (time/resources/money), and add these to your decision document:
How is the tool enabling team members to work more efficiently? Can you do a back-of-the-envelope time savings calculation?
On the other side, what is the cost of training people on a new technology? From a skill-level perspective, does the tool meet them where they are, or do they need to uplevel their skills?
How much effort/time would it take to integrate with your current system? Does that introduce any new hidden inefficiencies?
Their market positioning should help you: Every data tool on the market has had to “differentiate” themselves somehow. Who is best at solving my “must haves”?
Talk. to. people: 99% of your problems are probably familiar to someone else at the same scale of company/data maturity level. What does their community look like, and who else is using it, likely in their own unique ways, that you can talk to? Join those communities, you shouldn’t reinvent the wheel if you don’t have to.
A lot of this decision document framework is borrowed from the software engineering concept of the “architectural review.” Mozilla has their process publicly available here if you’d like to learn more!
Google it.