


Hiring Data Scientists With Intention
Reducing bias in your hiring process



I’m so excited to host my first ever co-authored blog! I met Tara Robertson in 2019 when I joined Mozilla, where she was the Global Diversity and Inclusion Lead at the time. When I needed to grow my team, Tara and I worked together to develop an inclusive hiring process. Since then, Tara and I have kept the conversation going and wanted to share some of our thoughts here!
Data Scientists are a versatile bunch, and the range of skills they need to have in order to be successful at their jobs is vast. As many data team managers have discovered while trying to attract new talent, there is no industry-standard rubric to hire for them, especially since the role itself is ill-defined. As a community, we are just beginning to learn how to standardize the interview process for different kinds of Data Science roles. In this post, we want to contribute to the evolving discussion by highlighting three areas that are worth putting some intentional focus towards to hire Data Scientists more inclusively:
Writing a focused job description that matches your team’s needs
Being strategic in sourcing to go beyond your network
Designing a structured interview process so that you can be consistent in evaluating candidates.
Writing a focused job description
Creating a new job description is not easy in any scenario, and a lot of hiring managers look to open job postings at other companies to get inspiration for writing them. Approaching it this way might seem to help with industry-wide standardization for hiring, but because the responsibilities for data teams vary drastically from company to company, there is a risk that managers can lose sight of what they actually need from that new hire, instead writing job descriptions that become a catch-all space to list anything they might need from their team in the future. The problem with this approach is that there will be good candidates who might shy away from applying for a role that they don’t feel qualified for.
To create a more needs-aligned job description, start with a longer-term vision for the data team based on how they should ideally be positioned in the company. This will vary given the organization’s data maturity; for example, is the data team in a very nascent stage, where you need full-stack data scientists who can tackle many different problems in a rapidly changing environment? Is the team underwater with ad hoc requests, where you might be able to leverage more junior Data Scientists who are eager to learn, and would grow as the team evolves to a more proactive state? Do you need to build out more foundational data models that can help enable data democratization, where Analytics Engineers would be a better fit than Data Scientists?
Counter-intuitively, it’s helpful to go through this thought-exercise without considering the current roles of the people you have on your team. Instead, this is a great opportunity to take a big step back and freely think through what the team as a whole needs to look like, and then plan steps to get there. With your goals in mind, assess your current team for strengths and weaknesses, and determine where you would like to bring in some new skills, and at what experience levels. There might even be growth opportunities for people on your team to shift their focus to new areas, which you should determine before deciding what skills and experience levels you really need to hire for.
Once you feel you have a job description that covers the areas you want to focus on for your next hire, it’s time to give it one more pass.1 The job description you publish is a representation of a real human who will join your team, and it’s worth considering that starting a new job is just one moment in their career. Finding someone who is motivated by new challenges means that by definition, they won’t check every box and will have some growth areas for the role you are hiring for. Frame the job description as part of a larger journey that includes their continued growth by paying attention to the team’s needs over longer time frames rather than only what you need in the short-term.
Being strategic in sourcing
Creating a diverse team starts from the very top of the funnel, and sourcing might be one of the most important yet overlooked stages of the hiring process.
For any hiring manager, forging a strong partnership with Talent Acquisition (TA) is key. If your company has high-level diversity goals, they should already be familiar with the business case for diversity. If not, be explicit about why you care about diversity in hiring–there are moral arguments, business arguments and innovation arguments. But sourcing isn’t just up to TA, it’s a critical part of a hiring manager's job too.
When hiring managers think of sourcing, we immediately think about reaching out to people we know in our network. On the surface, it makes sense; Data Scientists are also coached to develop networking skills and seek informational interviews by contacting prominent data teams on LinkedIn, attending conferences and meetups, and building portfolio pieces that lead to informal conversations with prospective hiring managers. In Mapping Exclusion in the Organization, Carboni, Parker and Langowitz state: “Networks are how people learn the unwritten rules of success, hear about job and promotion opportunities before they are posted, and — most critically — build a level of interpersonal trust and rapport with their contacts that translates into a willingness to pick up the phone and vouch for someone’s capabilities.” By building meaningful, trusting relationships in the community, you can be a node to share information and opportunities.
Something we discussed at length as we were writing this was how harmful bias can creep into the practice of leveraging networks for sourcing data science candidates. As humans, we are subject to in-group bias, that is, we naturally give preferential treatment to people who are in the same group as us, and our own network can often be a reflection of that. If your team lacks diversity, only looking to your own network while sourcing potential candidates will likely perpetuate the issue.
These network effects are not just limited to the hiring team. Informational interviews often lead directly into the official interview pipeline, and potential candidates who reach out to someone they know to learn more about a role gain an advantage. Because of the existence of in-group bias, DEI practitioners will say that the best practice is to be consistent with all candidates, which means hiring managers should either have informational interviews with everyone, or with no one.
This is the moment where some of you reading this might feel that disposing of informational interviews in the sourcing process is just not practical. That’s OK, Emily did too, at first:
When Tara and I first discussed this, it threw me for a loop. After all, I had just gone through the interview process myself, and had definitely leveraged my network connections to set up informal chats. In practice, informal conversations about opportunities are almost impossible to avoid, even when we are not actively hiring or seeking jobs ourselves. Data practitioners have formed into a tight-knit community, and we can’t unlearn what we know about former colleagues and contacts we have met during the course of our career. Additionally, the market for Data Scientists is on fire right now, and when I’ve been on the other side of the hiring table, there were at times thousands of applications for one role posting.
So, what do you do? There are a few ways to mitigate the effect of in-group bias and to give as equal of an opportunity as possible to all interested and qualified candidates. First, using the work that was done when crafting the job description, align on the key requirements for this job and what you’re looking for with your TA team. Work with them on their sourcing strategy for this role and how/where they will amplify the job posting.
When people in your network reach out to learn more about the role, encourage them to apply through the formal channels. Be thoughtful about any supplemental information you left out of the job description but that you might want to give in a 1:1 informational interview. If it’s truly helpful information, see if you can broadcast it more broadly, either with more open platforms such as Q&A sessions for potential candidates, or by working with TA to update your listing.
As you inevitably interact with your network while hiring, be extremely intentional about who you meet with, and during the interview process, be extra deliberate about hearing critical feedback about the candidates you have a prior relationship with. It’s also helpful to create an assessment of your network-homogeneity by mapping out the people you have the most contact with, including:
Your former teammates
The people you regularly interact with on LinkedIn, Slack and other professional networking sites
Attendees of the conferences that you’re a regular at
Alumni networks you’re a part of
Even when you are not hiring, expanding your network requires being proactive about joining new data science groups and networks that work hard to be inclusive, such as the Locally Optimistic community. There are several organizations that are committed to increasing diversity in tech hiring funnels, such as Women Who Code, People of Color in Tech, Code2040 and Outreachy, just to name a few.
Finally, find out what data your TA team collects about the hiring pipeline. Ask for demographic info (race/ethnicity, gender, disability, veteran status) that the TA team collects when candidates apply so that you can quantitatively analyze your hiring pipeline and find out where specific demographic groups drop off in the process. The insights you uncover might inform some changes you need to make in how you assess candidates.
Designing a structured interview process
There are many topics to cover when it comes to the actual interviews, and we’ll likely cover them in more depth in future articles. Here, we’d like to focus on the work to be done ahead of the process, before any interviews are conducted.
Set up an objective scoring rubric
Leaving assessment criteria vague or open-ended is one of the worst ways that bias can creep into a hiring process, as interviewers will naturally fall back on subjective instincts when making the choice of whether or not to advance a candidate. To mitigate this when putting together our own interview assessment criteria, we set up an extremely clear scoring rubric for each interview, again based on the most important attributes we had already settled on when we wrote the job description.
In our case, we were looking for three specific criteria for our Data Science hire: Coding skills, data intuition and communication, and we created a rubric for each of these that lined up with our internal applicant tracking system (ATS) software’s interview notes entry form. To illustrate this, here is an example of what a coding interview rubric might look like:2

Each interview had its own unique scoring rubric, shared with the interviewer(s) ahead of time. Once an interview was complete, the interviewer was instructed to write up their conclusion for each row or “attribute” in the rubric, whether it was a hard no, thumbs down, thumbs up or strong yes. We’ve found it’s best not to include an inconclusive or non-committal option. The interview questions should be crafted to give the interviewer a chance to assess every point, one way or another.
We chose to set rubrics at the level of the interview rather than for specific questions, gave the interviewers the standard questions ahead of time, and asked them to prep by seeing how they would answer those questions themselves. This way, the conversation was more casual, and interviewers could keep poking until they felt that they had assessed the candidate according to the criteria.
Another confession from Emily: It takes a lot of work to set this up, and even with the most thoughtful job description, it’s still difficult to imagine who is going to walk in the door once your team begins interviewing candidates. Something I hadn’t accounted for in my scoring rubric was what would happen if a great candidate came in at a seniority level higher than what I originally was assessing for. For some roles, there is flexibility in the title, and it may not be too uncommon for a more junior Data Scientist role to be filled with someone at a more senior level. In the future, to mitigate the risk that you hire someone under-level, I would put in the extra elbow grease and create a rubric for at least one level below and one level above the seniority level you are aiming to hire for. Referring back to your internal career ladder will help as you do this.
Signal over noise
There were some really great points made in this talk by Brooklyn Data Co. at Coalesce 2021, and the section on “maximizing signal” in interviews particularly resonated. Writing interview questions is an art, but it’s also the most important time to make sure the interview tests for what you care about most. Otherwise, fantastic candidates may not be given the chance to shine.
The interview process is essentially a classification algorithm, and the questions are the features that the algorithm uses to predict whether or not someone will be successful once you hire them. Thinking about it this way, it becomes clear that textbook interview questions such as “What is a t-test?” tend to have lower F1 scores:
“Type 1 Error” candidate hires, for example, those who had memorized textbook formulas and technically passed the interview but had less real-world experience and were prone to misinterpreting analysis results.
“Type 2 Error” candidate rejections, for example, those who have a great data intuition and lots of valuable product knowledge, but did not recently study up on formal statistics and failed answering the textbook questions on the fly.
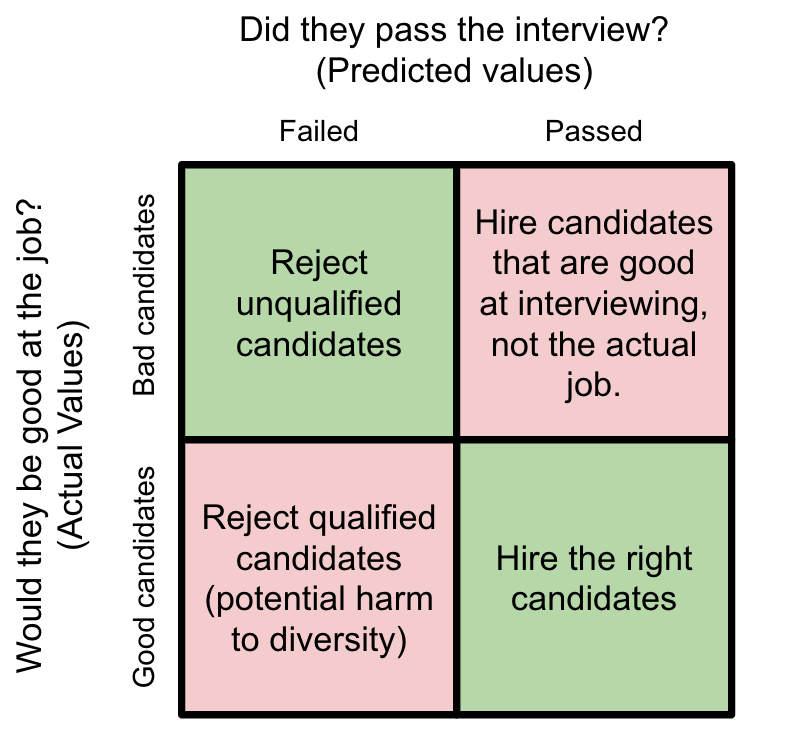
Here are some examples of how you might tweak classic data science interviews to move away from standard textbook data science questions and instead develop interview questions that are more fair in assessing what you really need from your candidates once they start the job:
Coding skills: Data Scientists rarely start from a blank CoderPad on the job, and would likely use pre-defined functions where possible. Think through what kinds of code your Data Scientists need to write on the job, and set up a paired-programming interview that would mimic that experience.
Data intuition: Instead of asking textbook statistics questions, use some mock data visualizations to walk through what kinds of narratives a candidate would build, and how they would check for biases in the data story.
Communication: In a business setting, Data Scientists often have to explain their findings to non-technical audiences. Instead of using solely “Tell me about a time”-type questions to assess communication, ask them to describe a technical topic that they are familiar with at a high-level.
Finally, be cognizant of people’s time and give them a great experience.
Giving take home exercises is common, and can be a great way to give people a chance to create a lower-pressure environment to demonstrate performance. But different candidates will have different levels of availability if for example, they are parents, are working full time and don’t have the financial flexibility to be on a break between jobs, etc. Take a look at the total number of hours you expect someone to spend on the whole interview process, including take home assignments. Optimize reducing the interviews, and focus again on the things that matter most to get a better signal.
Confession from Emily: I’ve definitely fallen into the trap of having too lengthy of an interview process for my candidates. Having gone through interviews myself very recently, especially through many of them at once, I have turned down companies that were asking too much of my time. Moving forward, I’m going to be extra cognizant in my own role as a hiring manager to make sure I’m being as efficient as I can to find the signal over the noise.
When all is said and done, as a hiring manager, you have to make a choice, which means that sometimes you will have to say no to perfectly good candidates. Data Science is such a small community, and a person’s experience in an interview will give them a lasting impression. Make sure it’s a good one. It’s a good thought-exercise to imagine what candidates would say about the interview process, even if they were rejected. Would they say they enjoyed the interview process, and that they felt it fairly assessed their skills? Would they say it was worth their (valuable) time investment? Would they consider applying for a job with you in the future, or recommend applying for jobs to their colleagues and friends? If something feels off, again, it’s best to address that as early as possible while setting up the interviews.
My guest co-author Tara Robertson is a diversity, equity and inclusion expert with nearly 15 years of experience. She was the Global Diversity and Inclusion Lead at Mozilla and is now a consultant that works with tech, engineering and data science organizations. She has a Masters of Library and Information Studies from the University of British Columbia.
It’s also worth mentioning that running the job description through something like Textio helps ensure the language will appeal to a broad range of candidates.
Last Emily confession: This is crafted mostly from memory as someone who hasn’t hired a new candidate in over two years. I would love to crowdsource assessments at this level with the data community, because creating these rubrics for specific jobs would be so much easier if we could all pull from some central “data interviews rubric repository.” Ping me if you have resources and/or would like to help with that.
 | A guest post by
|
A quick comment: I had to do a lot of processing to work out what "DEI practitioners" were.
A good and thought-provoking article. Here "down under" the data science community is even smaller, so I am interested in the out-of-group bias. If someone is not in my network or knows someone in my network that would be unusual, and a "red flag" in itself.